

이 글은 다국어를 예시로 들었으나, 번역 플러그인을 활용하는 것이 아니다. 별도로 번역본이 정리된 엑셀 등의 데이터시트가 있다는 전제 하에 그것을 와이어 프레임에 빠르게 불러오는 방법에 대한 내용이다.

우리는 종종 CTRL+C, CTRL+V 에 너무 많은 시간을 쏟는 것 같다. 특히 서비스 기획을 하면서 많이 느끼는데 그 중 다국어 작업이 그렇다. 다국어 작업이 힘든 이유는 크게 두가지다. 헷갈린다. 그리고 손이 아프다.
다국어 작업은 원래 이렇게 원시적으로 할 수 밖에 없는건가?🐒(우끼...)
왜 필요한가?
🐒 다국어는 헷갈려!
내가 해왔던 프로젝트들에서는 클라이언트가 번역업체에 별도의 계약을 맺거나, 사내 글로벌 마케팅팀등이 직접 작성하여 번역 문구를 제공해주곤 했다. 하지만 문제는 번역 문구가 오가는 과정에서 와이어프레임으로 전달 할 수가 없다는 것이다.
그럼 어떻게 전달하느냐....?
1. 와이어 프레임에 있는 모든 문구를 엑셀이나 워드에 옮긴다.
2. 엑셀 파일을 클라이언트에게 전달한다.
2-1. 클라이언트가 엑셀파일을 (사내/사외) 번역 전문가에게 맡긴다.
2-2. 번역 전문가가 엑셀파일에 내용을 채워 돌려준다.
3. 번역된 엑셀을 제공받는다
4. 엑셀에 있는 문구를 다시 와이어프레임 사본에 받아 적는다.
이렇게 보면 어려울 것이 없다.
하지만 저 번역 업무와 동시에 기획이 수정되거나 문구가 수정되기도 한다. 번역 문구가 누락되는 경우도 허다하다. (사실 한번에 누락이 없이 받는 경우가 더 드물다.) 번역 문구가 누락되면 1번부터 다시 시작하며 온갖 히스토리 범벅이 되고, 특히 워드로 수급받을 경우 그때그때 정리해두지 않으면 헷갈리기 시작한다.

그리고 가장 참담한 점은 그 언어를 모르기에 히스토리 이슈로 누락되는 실수를 잡아내는 것이 굉장히 어렵다는 점이다. 말 그대로 틀린 글을 봐도 멀뚱~히 볼 수 밖에 없다.
🐒 다국어는 손이 아파!
그렇게 제공받은 번역본을 다시 4. 와이어프레임 사본에 얹힌다. 유별난건지 모르겠지만 하루종일 CTRL+C, CTRL+V를 반복하자니 꽤나 멍청해지는 기분이 든다. 에이전시 특성상, 프로젝트 마감 후 다른 프로젝트 투입까지 휴식기 아닌 휴식기가 주어질 때가 있는데, 나는 이 시간을 활용해 어떻게 더 효율적으로 번역 문구를 관리할 수 있을까에 대해 고민을 했었고 내 나름대로 연구한 방법을 소개하고자 한다.

참고로 나는 학생 때 출판용이 아닌 소책자 작업을 할 때 이런식으로 작업을 했었다. 각 영역별로 텍스트를 한 곳에 정리하고, 데이터 싱크를 통해 한번에 꽂아버리는 방식이다. 갑자기 그런 생각이 들었다. 오프라인 툴인 인디자인으로도 데이터 싱크를 이렇게나 잘 활용할 수 있는데, 온라인 툴인 피그마로 할 생각을 못 했을까? 사실 원리는 똑같을텐데.
준비물
1. 문구가 정확하게 작성된 피그마 와이어 프레임
2. 다국어가 정리된 구글 스프레드 시트
사실 준비물을 간단하게 소개했지만, 아래 조건으로 사전 작업이 끝났을 때의 기준이다.
1. 문구가 정확하게 작성된 와이어 프레임
- 각 문구의 프레임 명이 #{문구}로 지정되어 있어야 함
2. 다국어가 정리된 구글 스프레드 시트
- 문구가 맨 앞의 시트에 언어별로 한 행으로 나열되어있어야 함
우선 사전 작업하는 법을 알아보자. 사실 어려울 건 없다. 아래에서 사용되는 플러그인은 모두 무료이다.
사전작업1: 각 문구의 프레임 명을 #{문구}로 지정하기
Step1. 모든 텍스트 레이어 선택하기
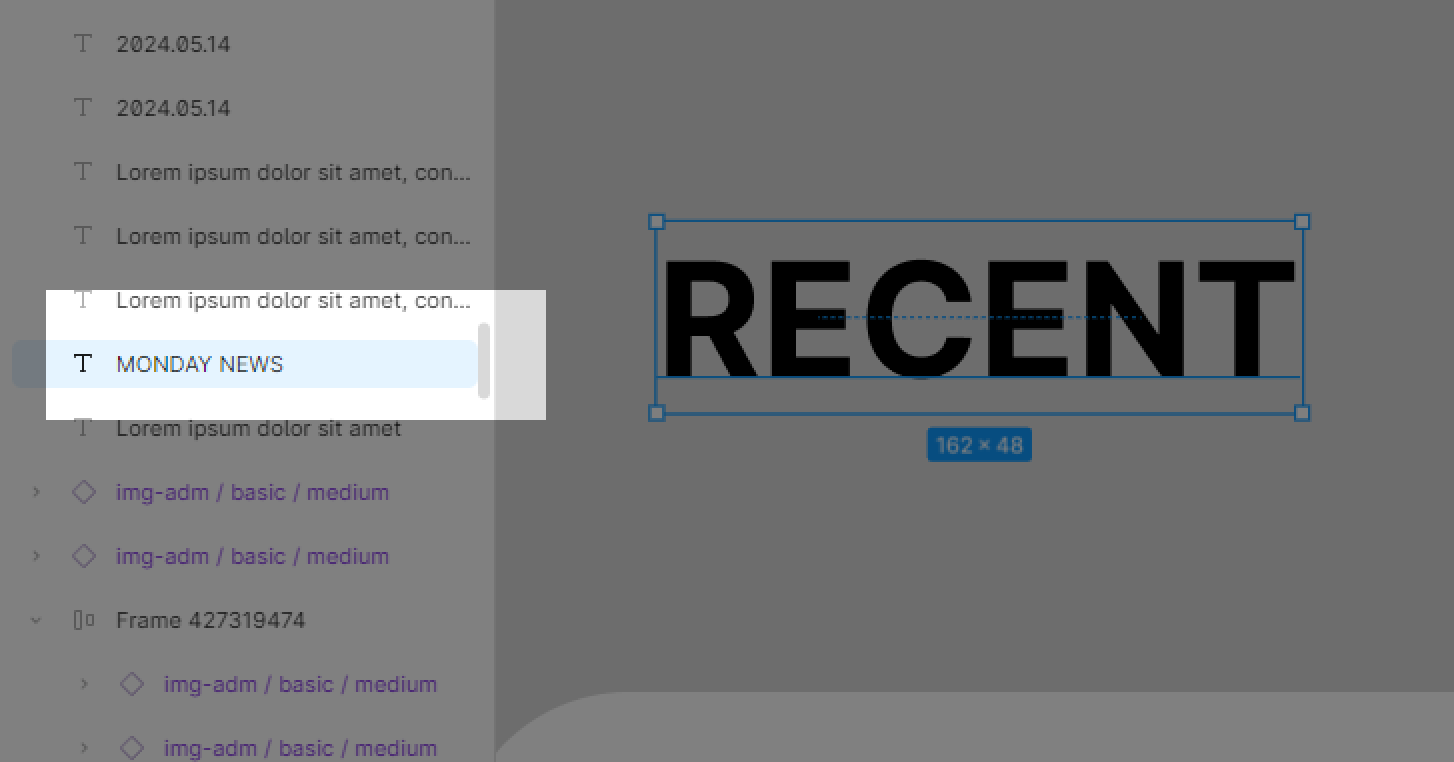
정신없이 작업하다보면 ALT키로 사본을 만드는 과정에서 실제 프레임명과 텍스트가 일치하지 않는 경우가 흔하다. 이렇듯 모든 텍스트 레이어의 이름을 실제 텍스트와 일치시키기 위해서는 우선 모든 텍스트를 선택해야한다. 아쉽게도 피그마에서는 자체적으로 '텍스트'만 모두 선택하기 라는 기능을 지원하지 않는다. 따라서 우리는 A Selector(링크) 라는 플러그인으로 모든 텍스트를 선택할 것이다.
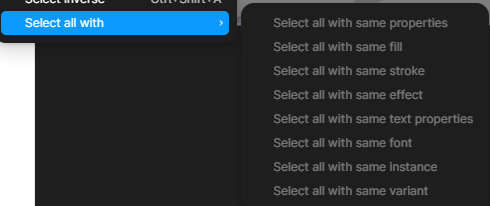
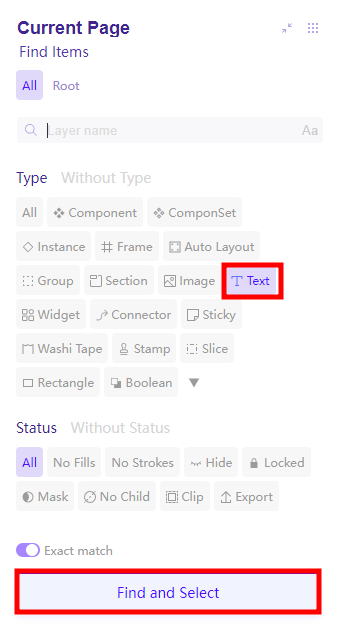
Text > Find and Select 를 누르면 해당 피그마 페이지 내 모든 텍스트 레이어가 선택된다. (테스트 결과 7천개이상까지도 잡힌다. PC 사양을 많이 따르는 듯)
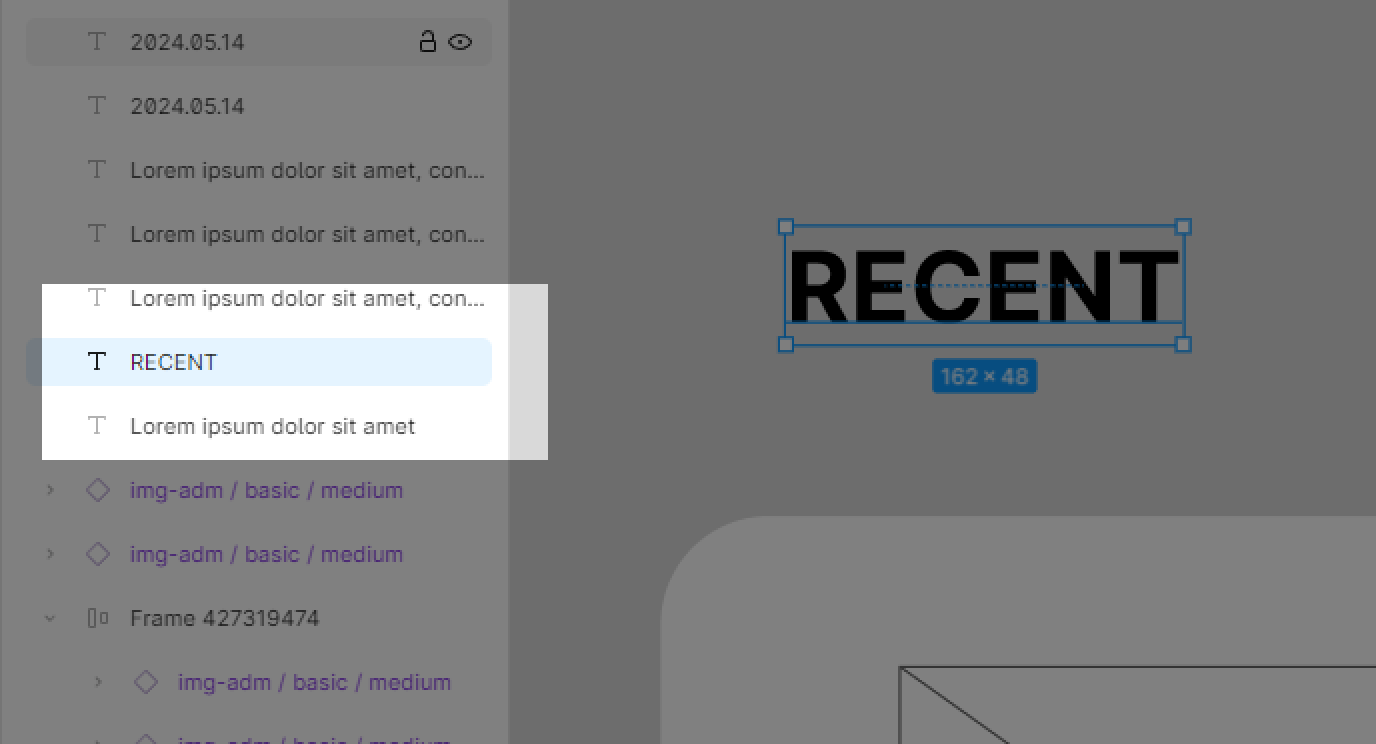
Step2. 텍스트 레이어 이름 원복하기
이제 실제 프레임명과 텍스트를 일치시키기 위해 Reset Layer Name(링크) 이라는 플러그인을 써보자.
Step3. 모든 텍스트 레이어 이름 앞에 # 붙이기
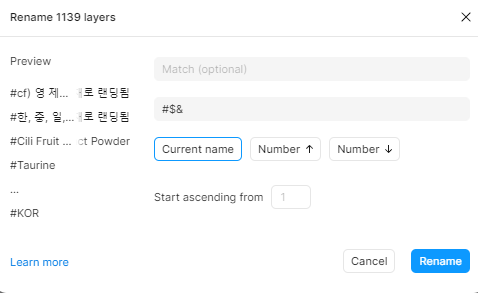
텍스트 레이어를 모두 프레임명과 일치시켰다면 CTRL+R로 레이어 이름 일괄 수정모드에 들어가 "#$&"를 입력해 #{현재 프레임명}이 노출되도록 한다. 레이어 명 앞에 #을 붙이는 것은 추후 이용할 Google Sync의 룰 때문에 그렇다.

사전작업2: 문구를 맨 앞의 시트에 언어별로 한 행으로 나열
Step1. 데이터 시트 복사하기
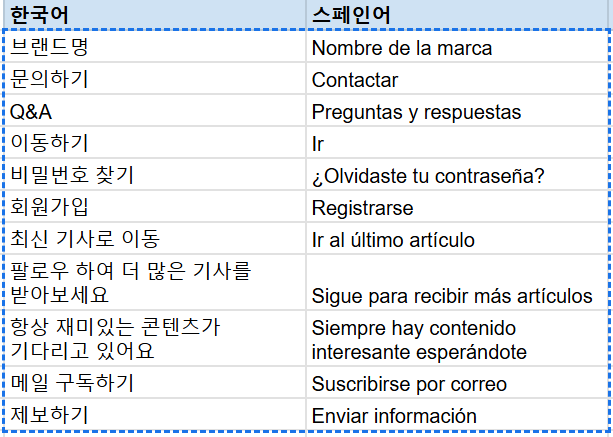
보통은 이런식으로 번역본이 온다. 엑셀이라면 내용을 구글 스프레드 시트로 내용을 옮겨오고, 실제 사용할 영역만 복사한다.
Step2. 데이터 시트 가로형 변환
Google sheet Sync 플러그인을 사용하기 위해서는 이 데이터 시트를 가로형으로 바꿔야 한다. 방법은 의외로 쉽다.
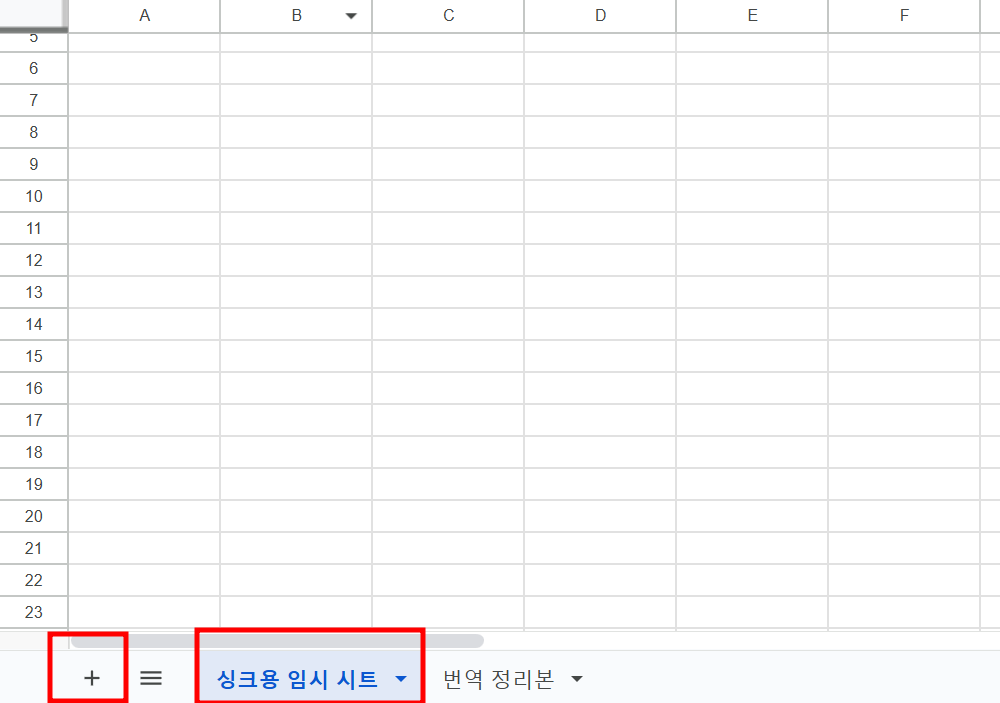
우선 싱크용 임시 시트를 생성한다. 이는 기존의 번역 정리본과 별도여야하며, 싱크용 시트는 최좌측에 배치되어야 한다.
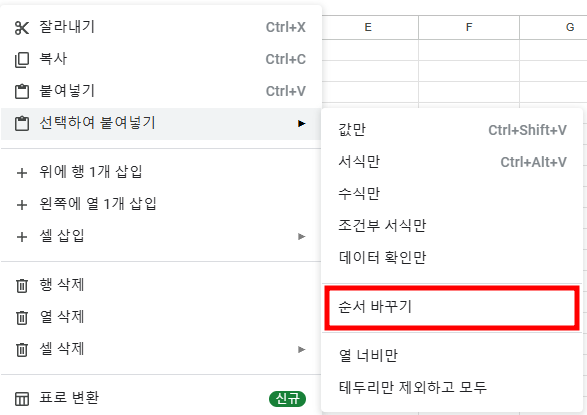

오른쪽마우스 > 순서 바꾸기를 통해 시트를 옮겨옴과 동시에 가로형으로 바꾼다.
Step3. 데이터 시트 권한 설정하기
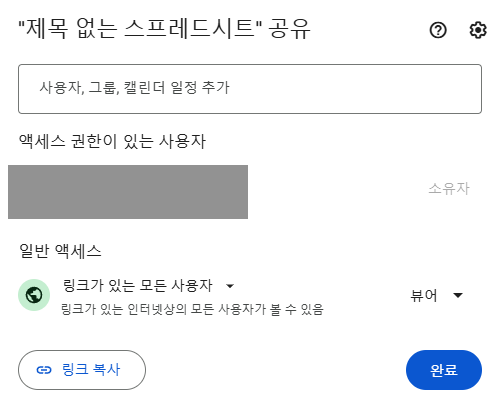
뷰어 이상으로의 권한을 설정하는 것을 잊지 말자.
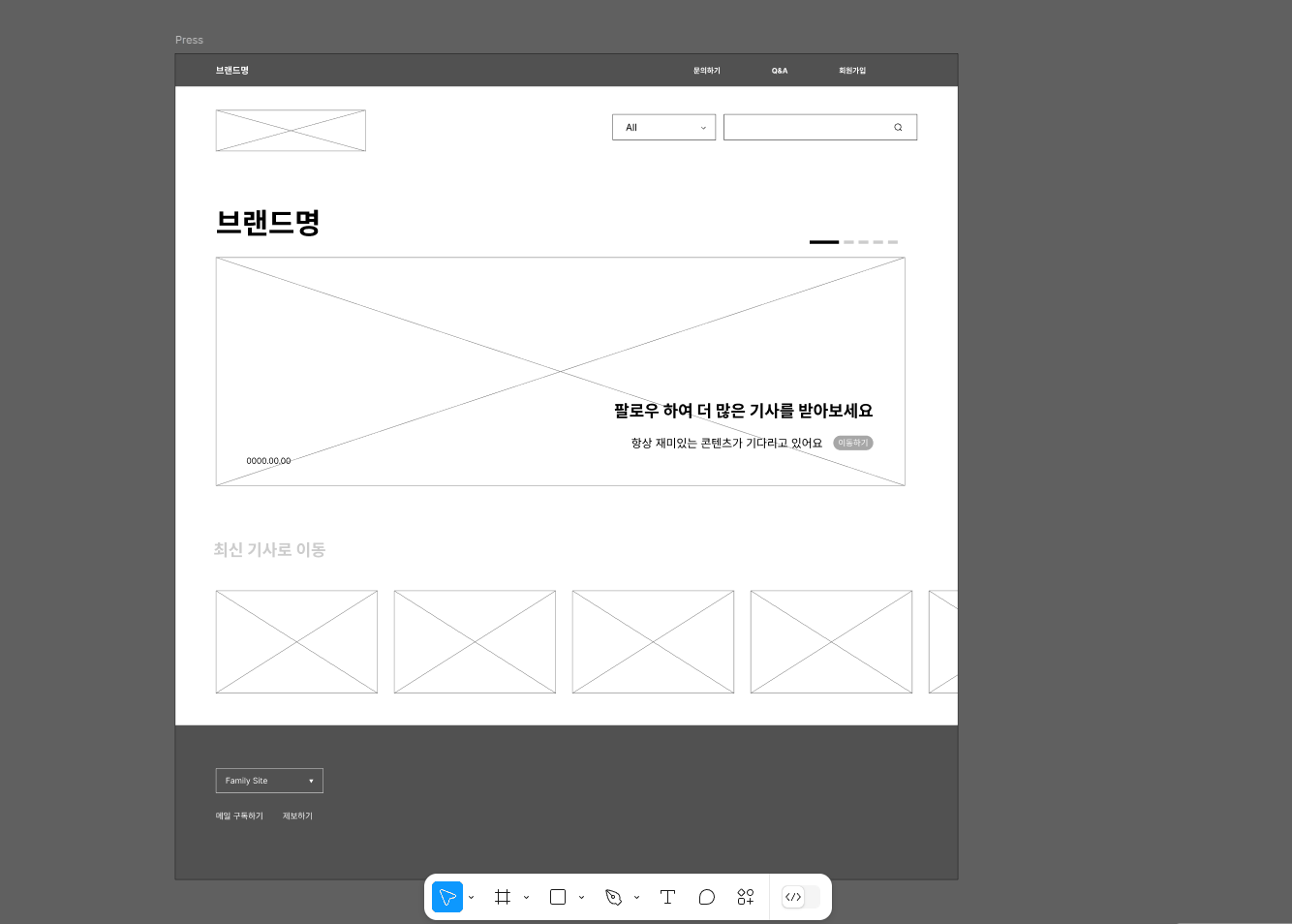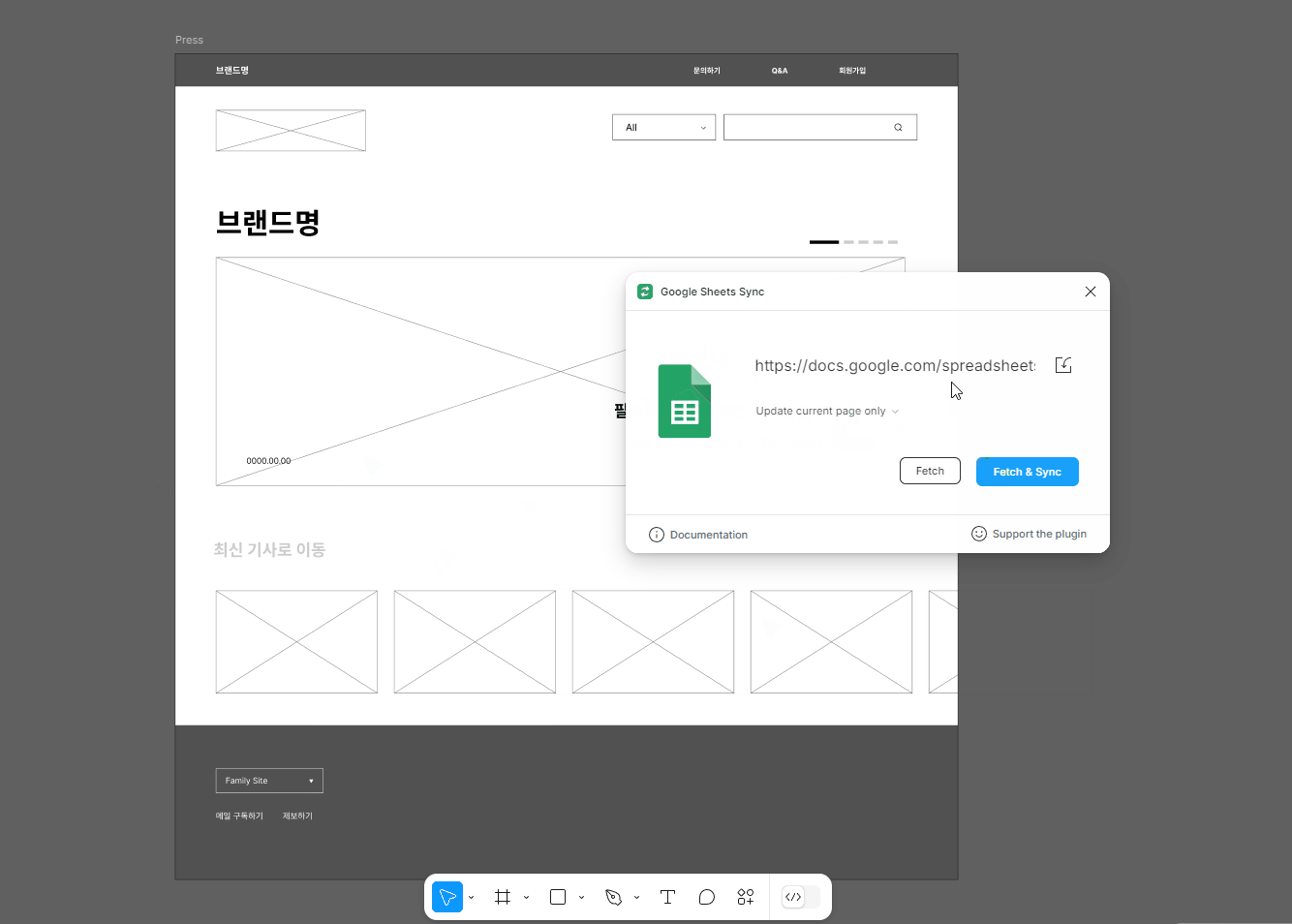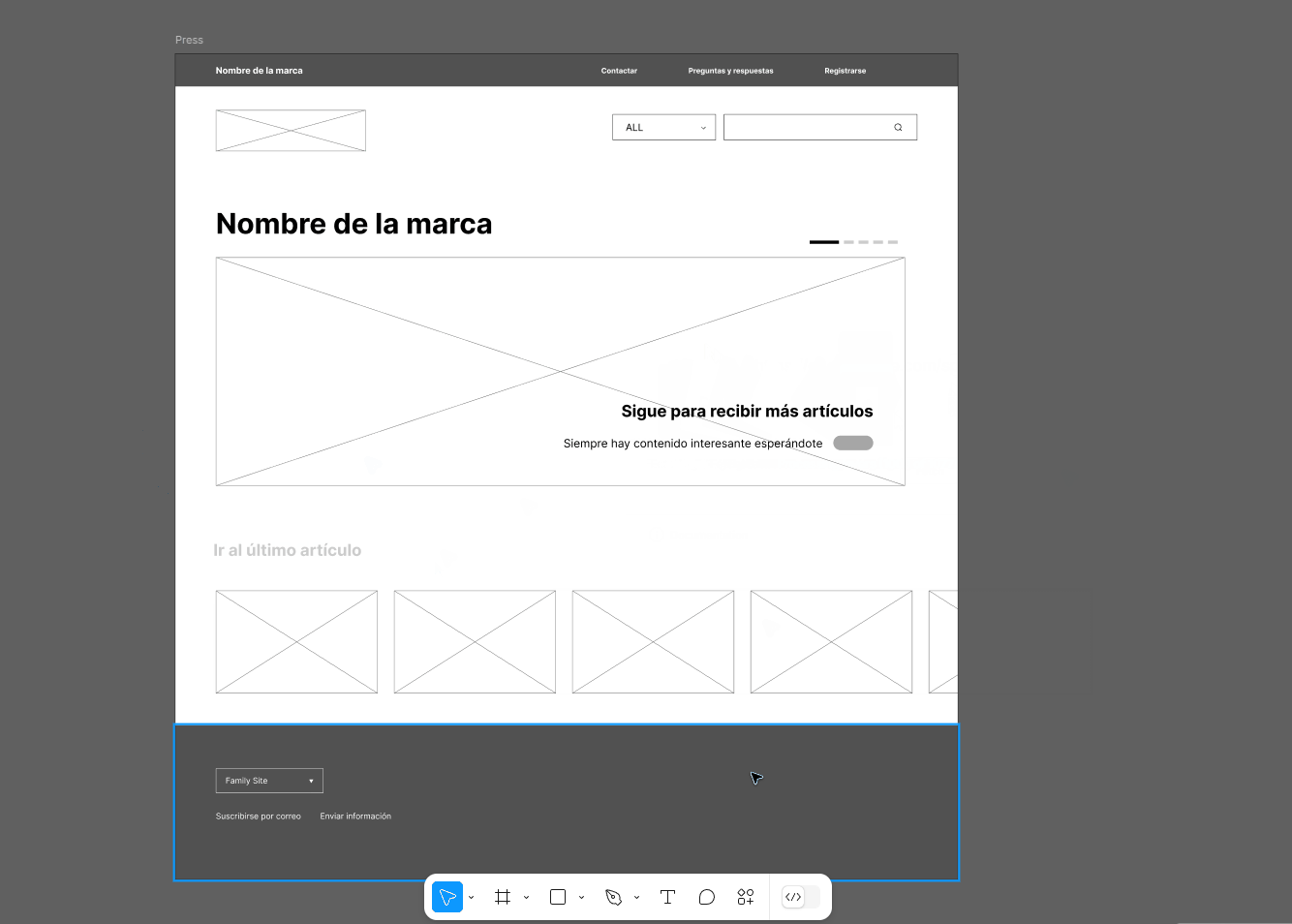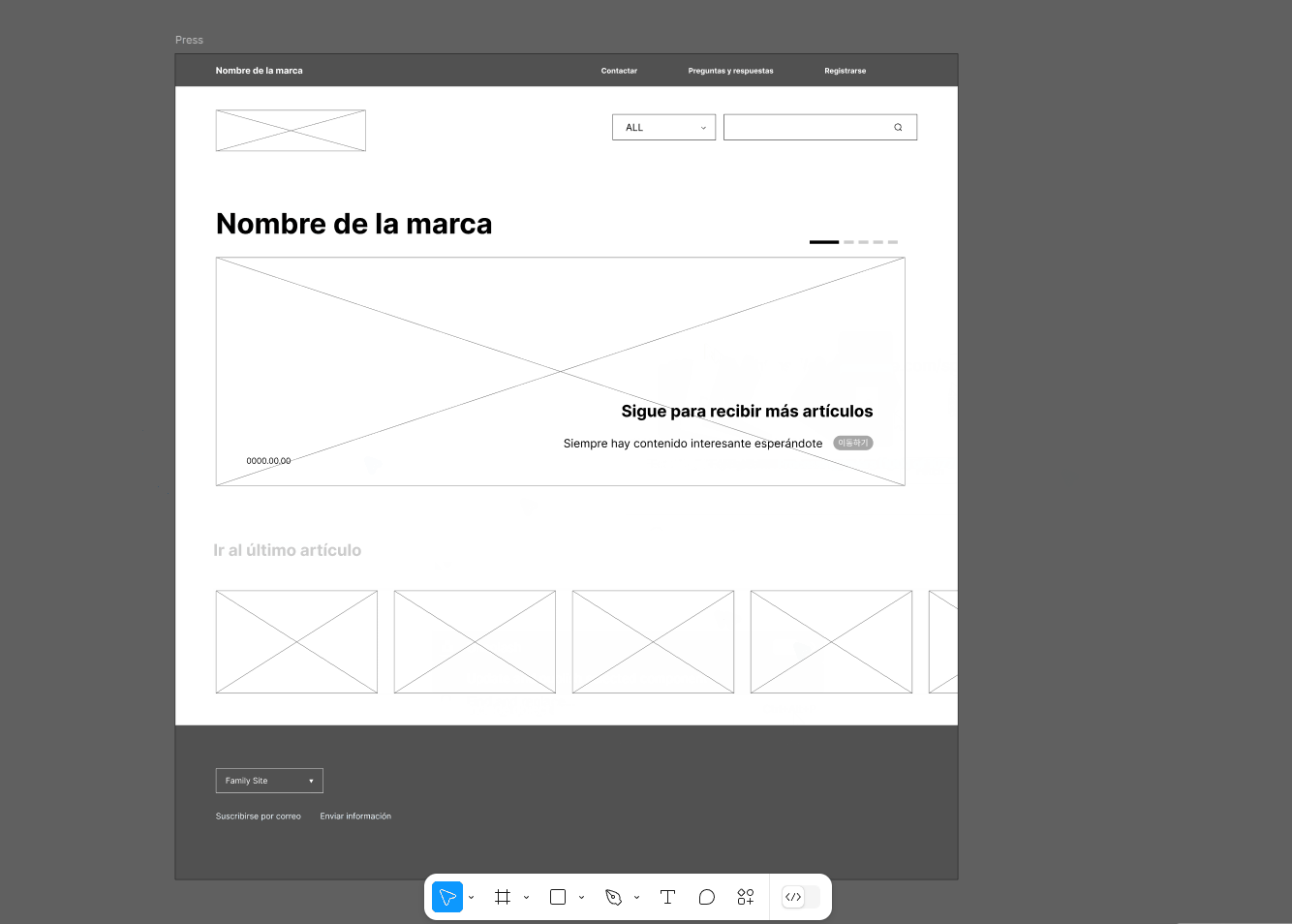
데이터 싱크하기
짜잔~ 이러면 사전 작업은 끝났다. 이제 제일 재미있는 싱크만이 남았다. 작업 중이던 피그마에서 Google sheet sync (링크) 에 들어가 위에서 작업한 스프레드 시트 링크만 연결해주면 된다.
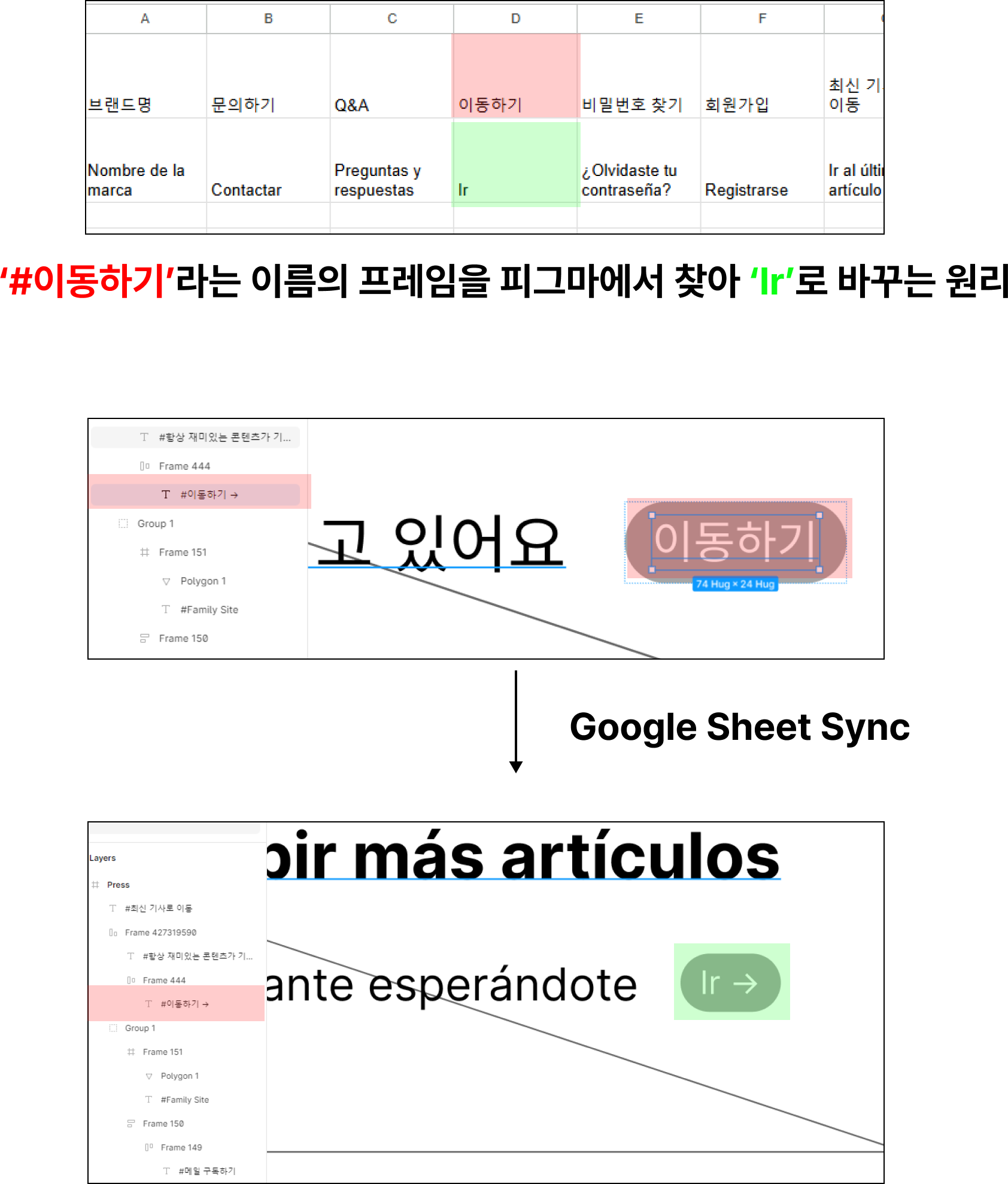
위 그림에서 보는 것처럼, 원리는 해당 구글 스프레드시트의 #{첫행} 으로 가공해 피그마에서 찾은 후, 아래의 행 내용으로 대치하는 방식이다. (프레임 이름은 유지된다)


이렇게도 활용해보세요!
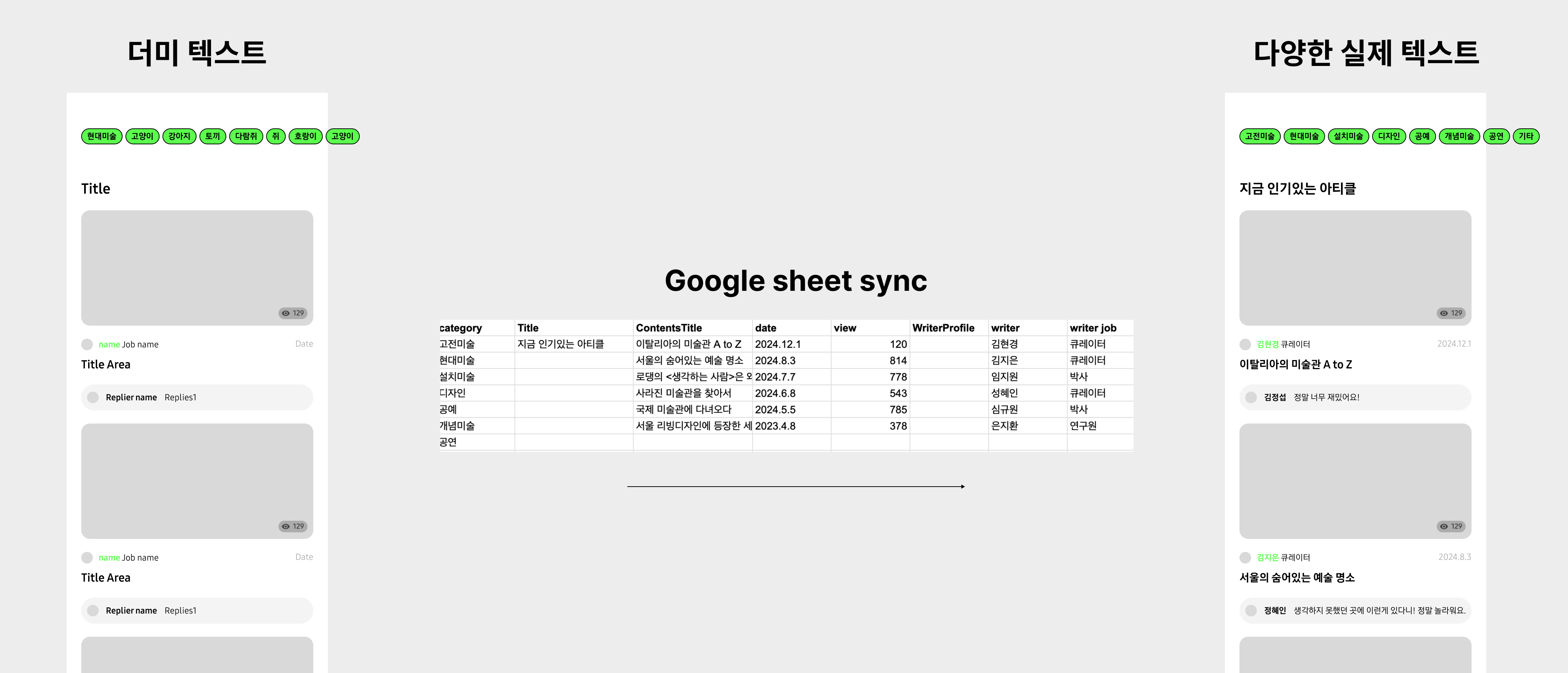
사실 예시는 다국어로 들었지만, 구글 시트를 연동하니만큼 무궁무진하게 활용할 수 있다. 가령...
- 버전별로 관리되고 있는 정책을 관리해야 할 때
- 더미텍스트를 추후에 실 텍스트로 갈아껴야 할 때
- 특정 문구 수정건에 대해서 광고주 확인이 자주 필요할 때
등등.....
레쓴런
컨트롤 씌븨와 함께한 지난 프로젝트로 느낀 레쓴 앤 런 타임. 그 외에도 알게된 짧은 토막지식도 넣어봤다. 아주 개인적인 경험에 근거하기에 틀릴 수도 있다.
1.
다국어 파일은 꼭 워드 말고 엑셀로 공유받자.
당연한 이야기지만 불가피하게 워드로 받았다고 하더라도, 무조건 엑셀, 노션 등의 데이터시트에 재업로드하여 관리한다.
*한-영 외의 다국어가 많을 수록 필수적이다. 각각의 언어를 담당하는 유관 통번역업체가 많아지기 때문이다.
2.
다국어 번역본은 절대 한 번에 끝나지 않는다.
총괄 문서를 만들어두고, 특히 번역과정에서 특정 문구가 바뀌게 될 경우 히스토리 관리를 하자.
3.
기준언어는 가장 긴 텍스트로 하자.
지원 언어에 아랍어, 스페인어, 독일어, 헝가리어, 몽골어, 태국어 등이 있다면 긴장하자.알고 싶지 않았다.참고로 한자는 제일 짧다. 위의 긴 언어들과 중국어를 같이 지원해야 한다면 BR태그를 처음부터 고려해야 한다.
*한국어가 상대적으로 짧은 이유는 조사와 어미를 활용하는 교착어이기 때문이고, 중국어가 제일 짧은 이유는 한글자 한글자가 각각의 의미를 가지는 고립어이기 때문이다. 아랍어는 줄글의 흐름이 반대이기에 인터페이스 또한 그에 맞춰 오른쪽>왼쪽 역순으로 변경된다.